Scraping UFC data with Python part 1
Previous blogs
[Part ?] - designing database tables
[Part 0] - scraping events data
[Part 1] - fighters table
Overview
As explained at the end of part 0, my next goal is grabbing the list of fights in each event. Each event in the events table has an event_link column linking to a table containing the full fight list and the outcomes of each fight.
i.e UFC 281: Adesanya vs. Pereira event_link returns this table - http://ufcstats.com/event-details/b3b6e80b7d5f8f0d
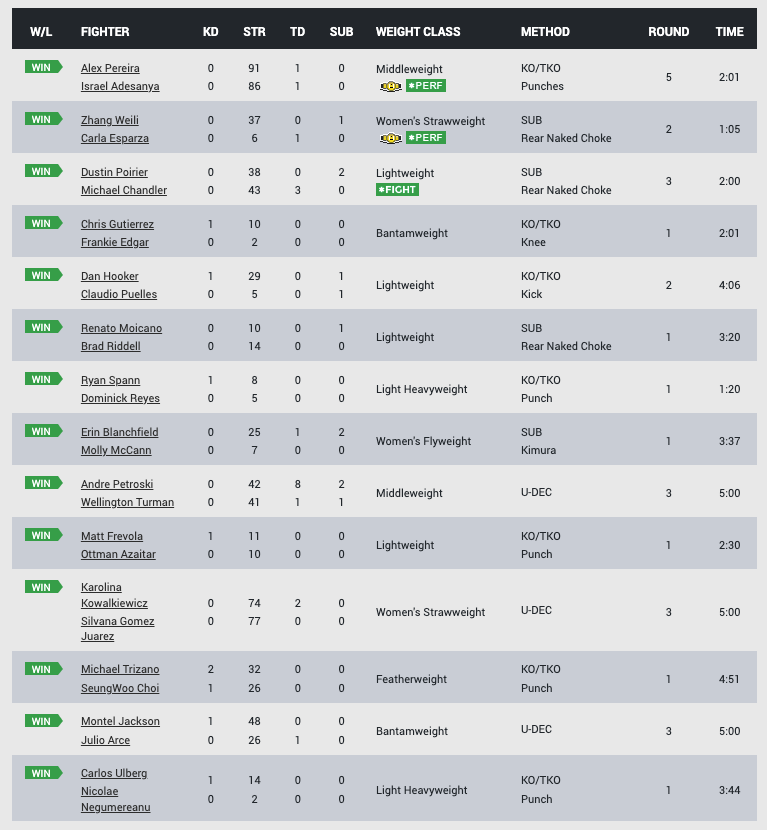
change of plan
The plan was to fill my fight_matchup table, that stores both fighters id’s.
Obviously this is only possible to do when I have foriegn key id’s in my fighters table, which I currently don’t, meaning the prerequisite to populating the fight_matchups table is to populate the fighters table beforehand.
ufcstats has a fighters table, containing a list of all ufc fighters;
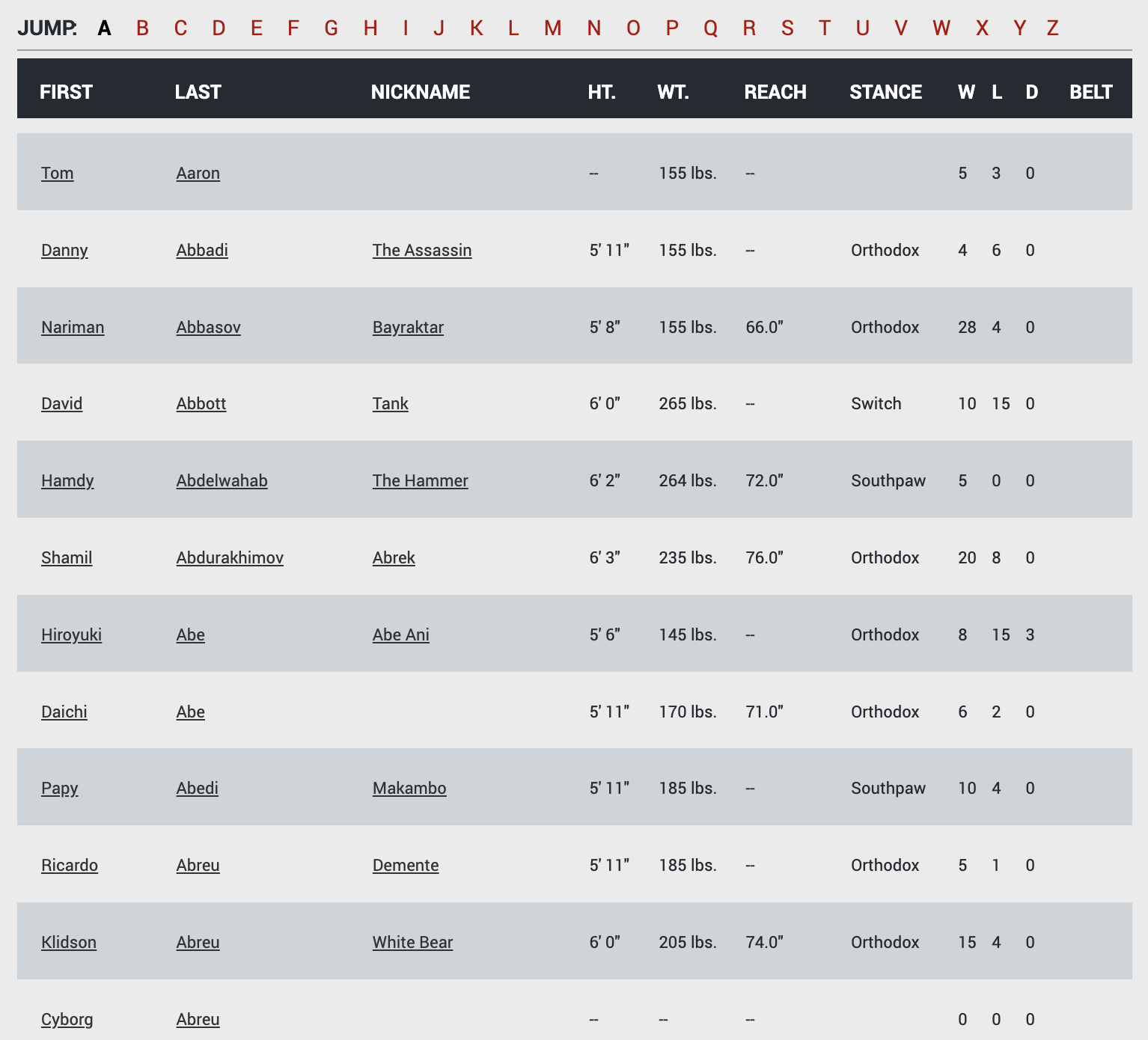 I will be grabbing all the rows of data in the above table, excluding the belt column for now.
I will be grabbing all the rows of data in the above table, excluding the belt column for now.
The above table only contains info above fighters with a lastname begnining with ‘A’, so to get all fighters on the roster I had to loop over each letter in the alphabet.
scraping the table
Creating the soup and targeting the table was exactly the same as my previous function used to grab the events data. However the contents of the fighters table is significantly different than the events table, with more rows and columns present here.
for row in rows[1::]: #first row void
data_cells = row.find_all('td') #each column
first_name = data_cells[0].a.string
last_name = data_cells[1].a.string
nickname = data_cells[2].a.string
#general info
height_string = data_cells[3].string.strip().split('\'')
ft = height_string[0]
inch = data_cells[3].string.strip().split('"')[0].split(' ')
height_cm = convert_height(ft, inch[-1])
weight_lb = data_cells[4].string.strip().split(' ')[0]
reach_inch = data_cells[5].string.strip().split('.')[0]
stance = data_cells[6].string.strip()
wins = data_cells[7].string.strip()
losses = data_cells[8].string.strip()
draws = data_cells[9].string.strip()
my solution was a somewhat messy use of .strip() and .split() functions, that worked nonetheless.
To loop over each character in the alphabet I used ascii_lowercase and called the parse_fighter_list func for each letter:
from string import ascii_lowercase
for c in ascii_lowercase:
parse_fighter_list(c): #loop over each character in alphabet
Again insert function differed very little to the function used inserting the events data;
def insert_fighter(f_name, l_name, nickname,weight,reach,stance,wins,losses,draws, height):
try:
cur = conn.cursor()
print('cursor testing')
cur.execute('INSERT INTO fighters (first_name, last_name, nickname, weight_lb, reach_inch, stance, wins, losses, draws, height_cm) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)',
(f_name, l_name, nickname,weight,reach,stance,wins,losses,draws, height))
conn.commit()
cur.close()
return
except BaseException as e:
print(e)
Once inserted the fighter table looked like this:
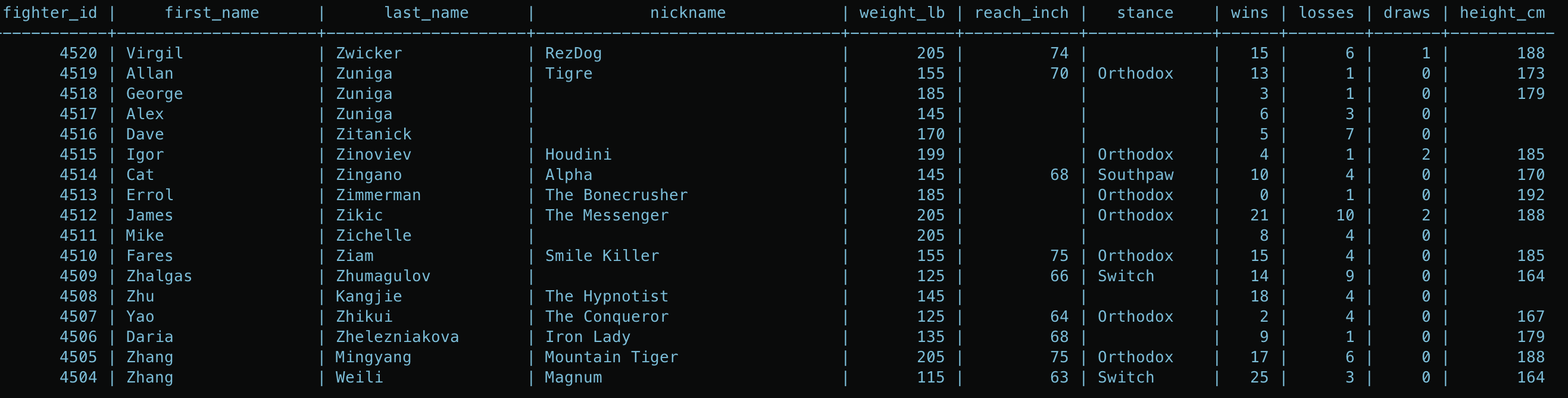 As seeen above the table ended up with over 4000 rows! More fighters than I expected I must admit.
As seeen above the table ended up with over 4000 rows! More fighters than I expected I must admit.
conclusion
with a complete fighter table, this project feel like it’s coming together nicely, and now opens a door to many possibilities.
The next blog will cover populating the fighter matchups table, that will use both event_id from the events table and fighter_id from the above table, with the goal of reducing potential data redundancy.